It’s Time to Zoom Out: Higher Education’s Responsibility to Think More Broadly about GenAI
Shyam Sharma (Stony Brook University),
Jing Betty Feng (Farmingdale State College),
Babette Faehmel (Schenectady Community College), and
Daniel Fernandez (Nassau Community College)
The criticisms leveled at higher education in recent years are varied, but they share an undercurrent of eroding public confidence, compounded with a sociopolitical environment that increasingly devalues public education and has been defunding it for a while. A broad and diverse segment of the public believes that college costs too much and delivers degrees whose market value is increasingly limited (which is increasingly true for most families). Universities are perceived by different segments of the public as ideologically skewed (e.g., too “woke”) or too removed from the interests of the broad public to be trustworthy (Stripling, 2026). While it is not yet mainstream, there is also the question about the university’s research mission: what have all the journal articles, the primary currency of academic research and its most expensive product, actually contributed to the lives of ordinary people, to democratic health, to public wellbeing?
Into this space of public skepticism arrive large language models (LLMs) such as ChatGPT and Claude, an application of “generative” artificial intelligence (GenAI), which offers a lot of potential benefits but also a lot more disruption than universities are equipped to handle. Broader AI technology, such as machine learning, has supported scientific breakthroughs and enhanced industry productivity for a long time. What is new about the LLMs is that they generate text probabilistically based on the patterns learned during training; their ability to produce human-like texts and perform reasoning-like tasks is undermining quality and rigor in many aspects of the academic work, from learning to research, while being driven by industrial force and private-sector agendas, which are deeply misaligned with the public commitments of higher education. While there is a growing backlash against the AI industry’s adverse impacts on many domains of academia and society, not many scholars and university leaders are explicitly addressing that misalignment. Many are instead clamoring to get on the bandwagon. Some of them argue that we must do more to prepare students for the “AI job market,” as if this will be the only or final technology in the infotech landscape during our students’ lives or careers. Others are too eager to integrate the technology into all of academic operations without asking where and how it helps and where we must create space for more independent foundation building. After a few years of trying “catch up,” it is time for scholars and academic leaders to speak from evidence of impacts (both positive and adverse), provide adequate support to faculty and students (helping them use the right tools in the right ways), and distinguish between the benefits derived by advanced or privileged users from their capable/responsible use and the harms to the learning of novices or less privileged users.
Silicon Valley, it is clear, does not care what we need for advancing our educational, research, or public-good missions. As one clear evidence of this, the sign up process of AI tools does not even include options like “student” or “teacher,” while there are very specific roles to select for industry jobs. The design and behaviors of most tools, including some that are designed to assist research, reading, and writing processes, are fundamentally at odds with how we define and perform those tasks in the university. So, educators, researchers, and institutional leaders should waste no more time before they get behind the wheels of decision about what kind of AI tools we need, what kinds we must resist, and how we are going to develop both tools and uses that align with our mission. It is time to zoom out and recommit to the broader mission society has entrusted us.
Trees and the Forest: Need for a Societal View
Obviously, higher education should advance the public good by fostering free and rational discourse while countering undue influence from external forces. Unfortunately, this role is threatened by three trends. The first trend consists of the pervasiveness of platform-based communication (Kissinger, et al 2021). There are few venues for communication today that don’t involve network platforms, that is, digital infrastructures supporting personal, professional and commercial interactions. Even face-to-face conversations are happening through such platforms, particularly with the advent of “wearables” that record one’s every conversation and activity. It is increasingly difficult to exist independent of network platforms because of the exit costs their users would face, with use of a smart phone having become a necessity without which one cannot navigate the modern world (Durand 2024). The second trend involves a growing market need to harness the value of data extracted from various communicative interactions. The network platforms through which communication takes place derive more value from the data that their users provide than from the outputs that the platforms produce. Ownership of this data is a key component to the market valuation of these platforms, while the users who provide such data are uncompensated (Varoufakis 2023). The third trend involves the integration of network platforms into higher education. Universities are increasingly pairing with the corporate network platforms for internal communication, teaching and learning, and civic engagement. Many mandate, provide, or support the use of specific AI tools, as well as increasingly using platforms and tools that are AI-integrated. This trend occurs in the context of the marketization of higher education and the need to prepare students to be “workforce ready”. But if the primary purpose of higher education is to make workforce ready graduates who have been trained using the technologies of network platforms, then at least three other worries arise.
First, there are worries regarding shared governance in the adoption of GenAI tools: consequential decisions are made without broad deliberation in the name of progress, competition, and service to students (such as tutoring or advising). Second, there are worries regarding academic freedom, specifically whether the surveillance function of corporate technology stymies free expression of dissent, as faculty and students cannot predict where the increasingly digitized and networked discourse will land. Third, if universities continue to constantly record, document, share the digitized data (including when coerced by unfriendly government bodies), the ideas and emotions of members of the community could fundamentally change the nature of higher education and its relation to the public good.
Higher education must view the tech industry as the ultra-powerful, unregulated, and ideologically driven financial and political enterprise that it is – an enterprise with self-interests that are so strong that they can warp the values and practices of those who use their products. When tech companies pressure colleges to adopt their products, often placing their personnel in advisory and regulatory roles, they blur the line between oversight and promotion, private and public discourse, process and product of communication, and the very agency and freedom of the users. Without adequate pushback from faculty and students, university leaders can face enormous social and peer pressures to “keep up with the times.” If we consider the enormous imbalance of money and power, it’s not hard to see how the industry’s push for university partnerships, freebie subscription to students, and difficult-to-opt-out AI features in educational platforms and tools, all serve as methods of subtle coercion toward industry interests. Academia has the social responsibility to resist against the tech industry, which members of the industry itself describe as proxy empires like the East India Company, or global structures that are capable of controlling the global knowledge economy (Suleyman, 2023). Scholars bear the responsibility to push back against Silicon Valley’s deterministic narrative that has sucked in politics, media, and other industries into a hype cycle that is designed to make the world order created by a few tech companies seem inevitable, the history they are seeking to write seem like the only path of human history.
Misaligned by Design: LLMs and the Research/Scholarly Mission
Universities and the AI industry operate from fundamentally incompatible frameworks for what knowledge is, how it is made, and who is accountable for any adverse impacts. The academic and scientific knowledge ecosystem, whatever its well-documented imperfections, is built on a set of long-established principles that require knowledge claims to be based on systematic inquiry and evidence: in fieldwork, lab experiments, community-based data collection, archival research, and so on. Methods of academic/scientific research must be transparent and documented in enough detail to allow scrutiny, replication, and accountability. Sources must be traceable to their authors and origins so that readers can evaluate authority, identify bias, and assess the basis of claims. And the entire enterprise is subject to peer review: the slow, demanding, imperfect but self-correcting process through which expert communities expose errors and build cumulative knowledge over time. These are the defining conditions under which knowledge earns public trust and becomes usable for medicine, policy, law, engineering, and democratic deliberation.
In contrast, privately controlled LLM systems are designed and marketed on categorically different terms and purposes. They are content processors that identify patterns and predict subsequent text trained on datasets whose ownership is proprietary, whose sources are not disclosed, and whose methods or operations are not accessible for scrutiny. The algorithms that weight, filter, and recombine this data are hidden behind black-box architectures (Mehrabi et al, 2021). When an LLM produces a literature review, a policy brief, or a research summary, it essentially makes a mockery of the intellectual processes by which scholars gather and analyze sources, credit ideas to accountable authors, systematically gather and analyze primary data, and seek expert review of their process and product. Advanced and responsible users can push back and force the tools to locate authors and cite sources; but there are few tools that are designed to meet the standards of academic scholarship, or publicly acceptable standards of any kind. If anything, tech companies are deliberately pushing new tools (such as Claude for Life Sciences, Google’s AI Scholar Labs, and OpenAI’s Comet browser, not to mention homework assistant tools) that are evidently designed and often explicitly advertised to scoff at established expectations of academic integrity and rigor.
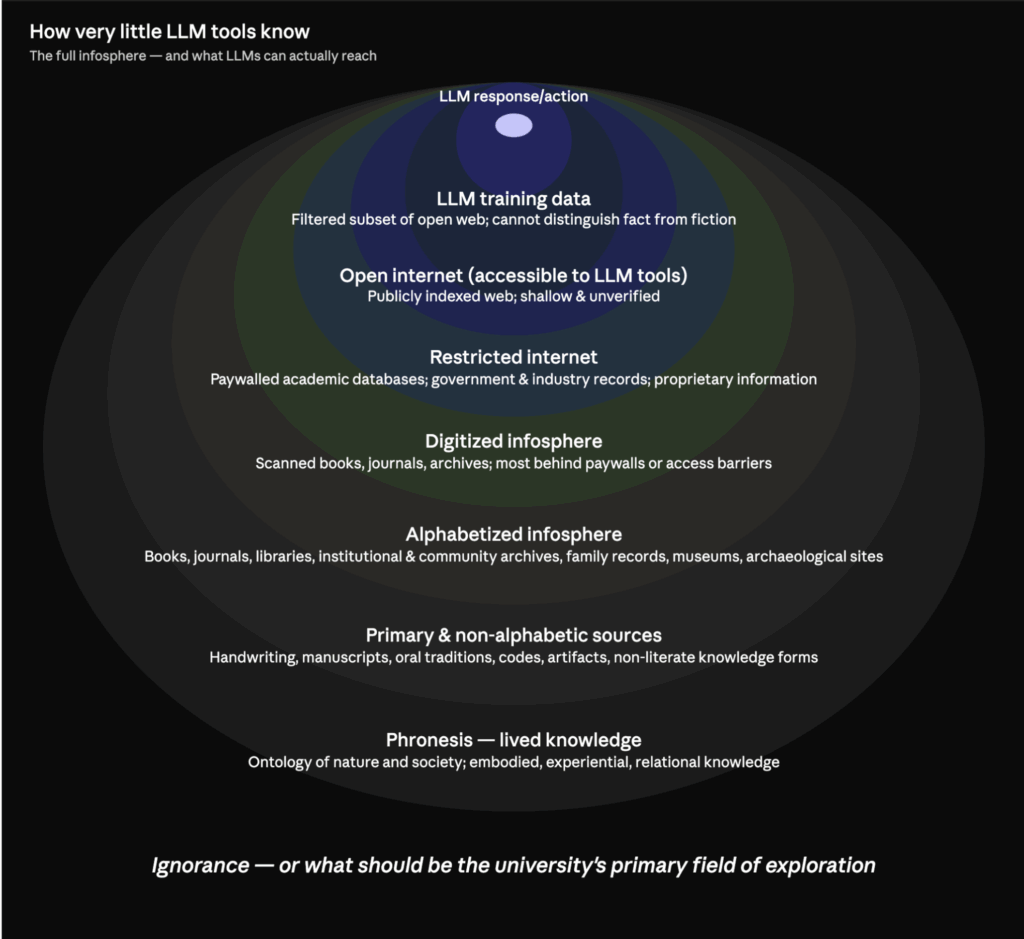
As the figure shows, LLM tools draw from a filtered slice of the open web and proprietary training data, assembled largely without properly referring to original creators. They still have very limited access to paywalled academic databases, government and industry records, or other proprietary information. Beyond the internet altogether lies a vast infosphere: print and digitized collections in books, journals, libraries, institutional and community archives, family records, museums, and archaeological sites; primary sources in handwriting, oral traditions, and non-alphabetic forms; and what the Greeks called phronesis (the lived, embodied knowledge of nature and society that scholars must learn from directly). Because we have created a culture where churning already published literature to produce new scholarship carries as much value as exploring the yet-unknown parts of nature and society, LLM tools are pulling students and scholars (who are under the pressure of often-perverse incentives) toward AI-synthesized sources within the above narrow limits. That wouldn’t be a problem if the tech industry’s accountability faced the stakeholders (instead of their shareholders and often unbelievably greedy men). The industry, such as Grok AI, has harvested training data often building on decades of disturbing datasets (posts from X/Twitter platform) (Crawford, 2021). As Marcus and Davis (2019) established in Rebooting AI, and as Narayanan and Kapoor (2024) document extensively in GenAI Snake Oil, the foundational code of today’s LLMs is plausibility, which, by definition, is not a standard academia can legitimately adopt.
The risks LLMs pose to the research enterprise are accelerating the corruption that was already spreading. Publish-or-perish cultures, citation-metric systems, and funding structures that reward output volume over socially responsible research have long distorted academic incentives and the value/quality of work. When properly scaffolded in the research process with human insights and responsibility, LLMs can help to spark ideas, identify overlooked patterns, and support theoretical advancement, and even support less resourceful scholars to achieve more discovery (Pattyn, 2024, Aguinis, 2026). However, LLMs are also helping scholars to respond to undue pressures to produce more and faster, helping many to become irresponsible to society – not to mention that automated or AI-dependent research outputs might pass through peer review and enter the scholarly record, creating a feedback loop that has no self-correcting mechanism. Given these risks, universities cannot adopt the private AI industry’s principles about information/knowledge, with no anchor in author or accountability, evidence or method, citation or credibility – as we can infer from how their tools function. For universities to embrace the AI industry’s newfangled norms about knowledge amounts to abandoning the foundational principles of the research enterprise of universities as public-service institutions.
Indeed, university leaders must realize why higher education is a prime target: we produce the knowledge economy’s most valuable raw material in the form of peer-reviewed scholarship, datasets, student writing, and faculty expertise. Not only is much of this freely available in the public domain, short of the paywall/middlemen that now serve, ironically, as the last line of defense for research integrity and even more intellectual property violation, no institutional safeguards exist against this threat to the reliability and rigor of the scholarly record or the respect for scholarly labor. LLM blackboxes are the inverse of the internet as a networked public space that early advocates of the web, such as Yochai Benkler (2006), were excited about. We believe that universities must remain the stewards of the principles that govern scholarly knowledge production, including citation practices, methodological rigor, and the public’s access to knowledge that it pays for. To survive AI-driven disruption, universities must resist the rewriting of these rules posted by external actors, and develop and build LLM systems that align with their social mission while remaining attentive to equity concerns.
We certainly do not defend the older status quo of paywalls, citation count, and journal impact factor; a more, not less, open knowledge ecosystem is necessary. We also acknowledge the value of LLM tools in the research process, such as to support method driven theory development. But it is clear to us that it is dangerous to use LLM tools to delegate critical parts of the research and scholarly process, exacerbating the worst corruptions brought about by neoliberalism, unethical pragmatism, and productivity-driven justification of socially harmful practices. Universities must not allow third parties that bear no consequence for making us bring about a tragedy of the commons especially when we know that that third party stands to gain enormously while doing so. That is, we are worried about uncritical acceptance and use of LLMs progressively devaluing scholarship in the name of overcoming scholarship’s “slowness,” which is actually typically required for deeper inquiry and intellectual accountability toward better addressing real-world challenges. The value of human intelligence in the research process is the rich knowledge of the contexts we live in, the in-depth observation of social and cultural phenomenons, and the personal lens and voices through active reflection. Excuses for using LLM tools as “writing assistants” similarly rest on shallow and irresponsible grounds: to the extent that writing is thinking, writing depends too heavily on context and disciplinary norms, expertise and evidence, values and responsibilities to be delegated to machines (no matter how powerful).
We are also worried about the longstanding disparity of investment in research and scholarship in higher education, across disciplines, campus types, public v.s. private sectors, GenEd foundations versus career preparation, educational versus research missions, faculty gender, and the zip codes of students. For instance, when wealthy students are able to engage in research activity during the summer, lower income students need to work full time to pay their next tuition bill – not to mention that resourceful high school students often game the system to pay for working on research and publications just to get into elite colleges or earn merit scholarships. Investment in faculty research by institution type is further exposed when disruptive new technologies put new pressures, giving cover for disproportionate investment in the name of urgency, opportunity, innovation, competition, and so on. University systems and institutional leaders should be cautious not to exacerbate the above inequities of investment. The entire system of academic publishing and knowledge dissemination has for a while been working as an exploitative business: journal publishers rely on the uncompensated labor of researchers, editors, and peer reviewers, performed in the name of scholarship and service, while placing published papers behind paywalled databases and profiting from charging institutions millions for access, unless authors pay thousands of dollars to make an article open access. The emergence of GenAI is likely to further amplify all these gaps, while also corrupting the research enterprise in many ways. It is time that university leaders made all these inequities their priority.
If we are really in the business of speaking truth and justice, even individual scholars must use the power they have to educate their students (often hundreds each year), to inform the broader public, to choose to use LLMs responsibly, and more. But academic leaders have additional responsibilities to help shape discourse and policy, programs and practices in the direction that they can defend with the visions and values they state for the university they lead. They have the responsibility to allocate adequate funding to adequately bolster General Education, to strengthen the Humanities/Liberal Arts, to support evidence-based and responsible application of AI technologies in STEM and medicine, and to show evidence of return on investment in ways that do not devalue some disciplines and missions and disproportionately dump resources on others.
Recommitting to the Teaching Mission
With the use of AI expanding across industries and well-paying jobs for college graduates declining, the growing reality of downward mobility has placed higher education in a challenging position as it seeks to prepare students for the future (Lichtenberg, 2026). Workforce readiness, employment rate, and average salary have become the dominant metrics by which students, parents, and – with increasing legislative force – public officials evaluate the value of a college degree. Students carry debt, face uncertain labor markets, and have legitimate needs that higher education is obligated to take seriously. The faulty hiring practice in the industry is perhaps one root cause as companies pragmatically emphasize the experience of particular toolkits rather than the transferrable competences a candidate brings. But the institutional response to that pressure has, in many cases, made the underlying problem worse: rather than deepening students’ capacity to understand the logic and application of emerging tools, curricula have shifted toward training in specific, currently marketable toolkits – skills legible to a hiring algorithm or a resume screener, but poorly suited to a labor market that is itself being reorganized by the same AI systems students are being trained to use. It is irresponsible to prepare students for jobs we are seeing being automated; we owe to the next generation broader conceptual understanding, deeper disciplinary grounding, and stronger interdisciplinary capabilities toward career success and social mobility. We may, in fact, need to update college curricula and experience for greater mental resilience, social skills, professional development, and character building.
Cloud-based AI systems can now complete basic data analysis, document synthesis, and writing tasks in seconds – work that once constituted the entry-level contribution of a recent graduate. The question many pose to higher education about this situation is worth pondering: if a graduate’s primary competency is operating tools that LLMs can now operate more quickly and cheaply, what exactly has the institution prepared them to contribute? An educator’s answer to this question should not be the same as that of the manager at a business: when a course in business communication teaches students how to write effective emails in complex contexts, a lot more can and should be taught and learned than to focus on whether a chatbot can produce an email as polished as a student’s. Regardless of what the tool can do, the educational focus is to develop in the student the capacity to gather and analyze information needed to write the email themselves, as well as to prompt the LLM tool to help them do so; it is to ask whether the tool’s output is appropriate, reliable, and adequate for the specific problem at hand. The practice of writing that business email is NOT the educational goal: it is to develop all the knowledge, skills, and habits of mind needed to write or evaluate the email (written by a machine or another human being). The email in a college classroom is not a means of getting something done; it is a sandbox for making learning happen.
The need for broader knowledge and skillsets is not new: it is what higher education has provided for a long term (from the Greek trivium to modern general education). The tech industry is arguing that a strong foundation of knowledge and broad skillset are no longer required – as if we don’t understand whose interest that view of education serves. We must study a little history of technology to understand the dynamics of power in the full landscape of today’s information technology. We must understand technology as encompassing tools, skills, methods, and applications (in the Greek sense of techne), understanding not just what a tool does, but what it is for, what assumptions its designs and now behaviors embody, and where it fails to meet the user’s needs or values. It is time to recommit to general-education foundations in ways that teach students the numbers and operations before they reach for the calculator (to use a limited analogy); and it is time to situate “AI literacy” as one among many kinds of overlapping literacies, ranging from the alphabetic, visual, information, financial, civic, statistical, scientific, cultural, and ethical to the embodied literacies of craft, care, and practical judgment that no automated system can model or replace.
Underlying the teaching mission is a question that is quite disturbing: who gets to develop genuine intellectual capacity, and whose education is reduced to mere grades and degrees on paper? In the name of job-readiness, students in community colleges, open-enrollment universities, or institutions with the least political and financial leverage often create curricula that are narrowly designed for “job-ready” outcomes. While the pragmatic concerns are real, both the state and the institutions should find ways to make education more affordable for all students, giving all students the time and investment it takes to lay a stronger foundation for lifelong success. If higher education is to resist rather than reinforce economic stratification, the less well-resourced institutions must bolster gen-ed foundations, foster critical thinking, and cultivate intellectual breadth across the curricula – thereby preparing students to survive at least the next few technological disruptions and social/professional transformations. If we merely prepare our students to operate the latest, shiniest tools, their education will be obsolete or automated even faster.
The challenge (and especially vulnerability) is the most striking at community colleges and open-enrollment institutions. Faculty at two-year colleges carry high teaching loads, operate on slim budgets, and work with students who are often simultaneously employed and carrying care responsibilities. Those students come to college, reasonably enough, for skills that will improve their material circumstances. Many have had little prior exposure to information or digital literacy in any formal sense. And they are not immune (nor should we expect them to be) to the message, delivered from prominent platforms and credible-seeming sources, that AI proficiency is the key to professional success. When Google’s chief marketing officer tells an audience at Harvard Business School that understanding AI will help students “land not only a good job, but meaningful work for the rest of their lives,” that message might be debated further there, but when it reaches community college students,they are less capable of doing the same because the capacity for a critical interrogation of such messages aimed at “workforce development” is significantly more thin at two year institutions. At the community or state-run college, a writing instructor or a librarian will struggle to counter the narrative without institutional backing.
But community colleges would betray their own declared mission if they uncritically adopted the AI industry’s account of what their students need. The mission of a two-year institution is not to produce platform-legible outputs; it is to educate lifelong learners and informed participants in community life. No one can say with certainty what the labor market will look like when today’s students graduate, a lesson the Covid pandemic taught with some force. What can be said is that the capacities most durable across disruption are those least amenable to outsourcing: the ability to ask relevant questions, to withhold judgment pending adequate evidence, to connect new information to existing knowledge, to recognize one’s own assumptions. These are not soft skills appended to a technical curriculum; they are the foundation on which any curriculum, technical or otherwise, must rest if it is to serve students beyond the immediate moment.
Those capacities are still most reliably cultivated through meaningful human-to-human exchange, the productive friction of genuine disagreement, and the slow, recursive work of deliberative thinking. Only other humans genuinely push back, make us uncomfortable, and remind ourselves of our social and ethical obligations to one another. In the humanities courses that many community college students will encounter only briefly (perhaps a single semester of writing or philosophy on the way to an Associate Degree) that dimension of education is not a luxury to be traded away for efficiency. It is the irreducible core of what it means to educate rather than merely train. The institutional question is whether higher education, under present pressures, still has the will to insist on that distinction, and to make the public case for why it matters.
Conclusion
We call for immediate attention and actions from SUNY and higher ed institutions as the situation couldn’t be clearer: a handful of private companies, accountable primarily to their shareholders, are rewriting the rules of knowledge creation, teaching, and learning – while too many of us within higher education are sleeping at the wheel of our social responsibility. We deem an ethically driven resistance urgent; such resistance must come from everyone who takes higher education’s public mission seriously. It is a shame that the resistance is often framed as “disliking” AI or being a “Luddite”; there must be good reasons why the most well informed about AI within academia, in addition to dozens of early pioneers, are sounding the alarm bells. Educators and academic leaders alike must not cede decisions about AI adoption to the industry that profits from it; we must refuse to normalize practices that bypass the standards of evidence and ethics the academy exists to uphold, and we must make the public case loudly and concretely for why those standards matter.
The best path forward is insistence on our own foundations of values and principles, built over centuries, that we must build new practices upon. If no country changed its entire constitution when electricity or the train or computers were invented, no university or scholar needs to abandon or replace how research methods are applied and sources of information are revealed. If students must understand numbers before reaching for the calculator, they must also develop adequate knowledge, skills, and agency before starting to “collaborate” with LLM tools. AI literacy must be taught but as one literacy among many. It is only on these foundations that can enable future generations of researchers and scholars, professionals and citizens to ask complex questions, seek valid evidence, and take responsibility toward a reliable knowledge ecosystem on which both universities and democracy depend.
Books Referenced
Benkler, Yochai. The Wealth of Networks. Yale University Press, 2006.
Crawford, Kate. Atlas of AI. Yale University Press, 2021.
Marcus, Gary, and Ernest Davis. Rebooting AI. Pantheon, 2019.
Narayanan, Arvind, and Sayash Kapoor. AI Snake Oil. Princeton University Press, 2024.Suleyman, Mustafa. The Coming Wave. Crown, 2023.